
Data Scraping is basically a process of extracting data from a website using some scripts or automation tool/software. In this demo, we have to scrape the review and information about the doctors from various medical field-oriented websites using Scrapy and Selenium tools.
Purpose of the Web scraping:
The list of things you can do with web scraping tools is almost endless. I have put some of the most common ones below.
Job Aggregator:
There are people actively looking for jobs and there are companies looking to hire suitable manpower. The problem is there are a ton of job boards with a lot of listings. What if you can scrape the job links and title, put it in a single place from where the job seeker can get the details.
Scraping Reviews:
Reviews are important for businesses to know better about their customer. This gives the better understand of their customers & improve their services.
Brand Monitoring:
In today’s highly competitive market, it’s a top priority to protect your online reputation. Whether you sell your products online and have a strict pricing policy that you need to enforce or just want to know how people perceive your products online, brand monitoring with web scraping can give you this kind of information.
Price Monitoring:
Price monitoring is a very common yet useful technique that we can use to automate the process of checking prices on various websites.
Demo Video of Physician Reviews scraping using Scrapy and Selenium
This is a demo of a data acquisition pipeline to search directories and extract physician reviews, ratings, review date, reviewer information, physician details using Scrapy and Selenium.
Demo Medical Websites:
https://my.clevelandclinic.org
Scrapy:
Scrapy is a python crawling framework, used to extract the data from the web page with the help of a selector based on XPath.
Selenium:
Selenium is a UI automation tool used for data scraping. Scrapy is a very powerful web scraping framework, however, it has some limitations. Eg: If we need to extract a mobile number from healthgrades.com or similar sites, but the mobile number is displayed only after the user clicks the “show mobile number” button, we need to use Selenium for data scraping to execute the click event.
MongoDB:
The scrapped information like the review text, date, rating, reviewer details, physician details, etc., are stored in a NoSql database like MongoDB. MongoDB is an open-source document database and leading NoSQL database. MongoDB uses the following hierarchy of artifacts to store information. They are
Database:
The database is a physical container for collections. Each database gets its own set of files on the file system. A single MongoDB server typically has multiple databases.
Collection:
A collection is a group of MongoDB documents. It is the equivalent of an RDBMS table. A collection exists within a single database. Collections do not enforce a schema. Documents within a collection can have different fields. Typically, all documents in a collection are of similar or related purpose.
Document:
A document is a set of key-value pairs. Documents have dynamic schema. Dynamic schema means that documents in the same collection do not need to have the same set of fields or structure, and common fields in a collection’s documents may hold different types of data.
The following is a class diagram of how the review data scrapped is stored in the Mongo database.
Flow Diagram:

Process Explanation:
First, we have to identify the target website and then collect URLs of the pages where we want to extract data from.
Once we make a request to these URLs our scrapy spiders crawl websites and return the HTML of the page after that we have to use locators to find the data in that HTML. Once the Data extracted, we can save it in our database.
For extracting the data from HTML we can use either CSS selector or XPath.
Scrapy itself having a lot of features for format the data store it into various kinds of databases either SQL or NoSQL without hassle.
Sample Screenshot of scrapped data:
Parent Table: (Doctor details)

Child Table — (Review details)

Source Website Screenshots

https://www.ratemds.com (* VPN Required)

https://my.clevelandclinic.org

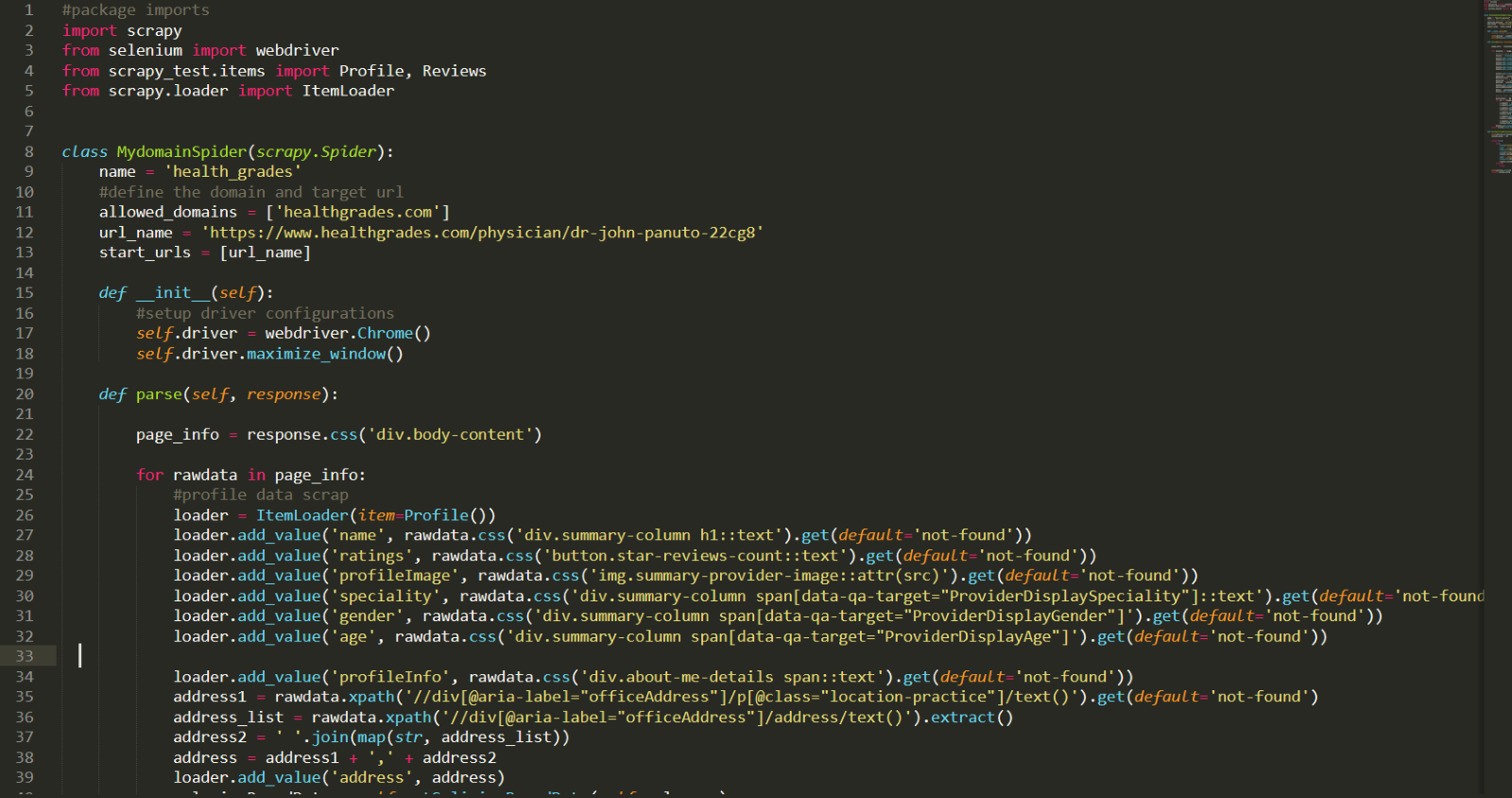
Scrapy code sample: Screenshot
 Written By:
Written By:
Veerakumar M
Data scientist with 5+ years of experience leveraging Statistical Modeling, Data Processing, Data Mining, Machine Learning, and deep learning algorithms to solve challenging business problems in Natural Language Processing (NLP), Text Analytics, Chat-bots, and Full-stack web development.
