The idea of this project is to build a sentiment analysis model that detects the emotions that underlie a tweet. It makes associations between words and emotions and the aim is to classify the tweets into sentiments like anger, happiness, sadness, enthusiasm etc. rather than the usual sentiment classification that only involves truly contrasting sentiments of Positive and Negative.
We have considered 3 different approaches to build this Social IQ analysis pipeline. They are
- Universal Sentence Encoder
- Doc2Vec
- LSTM
The performance of each of these approaches are explained below.
The Data:
The data can be downloaded from GitHub — https://raw.githubusercontent.com/tlkh/text-emotion-classification/master/dataset/original/text_emotion.csv
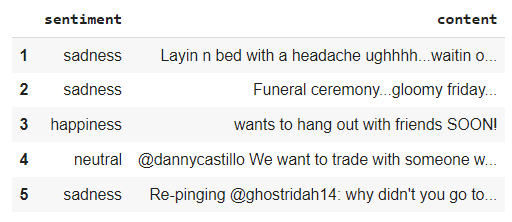
The data is in tabular form and each row is divided into 4 columns namely the tweet_id, sentiment, author and content.
The tweets in the data are pulled from Twitter using Twitter API as additional training data. The tweets are classified with their own hashtags — for example “#happy” as the hashtags should be an appreciably good (but far from perfect) representation of the sentiment of the tweet.

Exploring the Data:
The dataset contains 40,000 tweets which belong to 13 Sentiment labels in total and these sentiments were Neutral, Worry, Happiness, Sadness, Love, Surprise, Fun, Relief, Hate, Enthusiasm, Boredom, Anger.

As we can see from the about data visualization, the sentiment classes are very much imbalanced and several of those classes were in fact extremely similar. And hence we combined several of those classes into four final classes and these 4 sentiments that were considered for Analysis are Happiness, Sadness, Neutral and Hate.

Pre-processing:
The columns of tweet_id and author are irrelevant for analysis and hence these columns are dropped from the Dataframe and only the content of the tweet and its respective sentiment label is considered.
The content of the tweets contains special characters like @, #, etc., which are removed. And all the words were converted to lowercase.

Models Analysis:
Universal Sentence Encoder:
The universal sentence encoder model encodes textual data into high dimensional vectors known as embeddings which are numerical representations of the textual data. This is a semantic indexing model that has many uses like text classification, semantic similarity, and clustering. This model was chosen for the main reason that it requires no training data and it works on the principle of Semantic similarity.
Know more about USE here: https://tfhub.dev/google/universal-sentence- encoder/1
Approach:
USE compares two bodies of text and then gives the similarity score between them. One body of the text is the tweets. The other is the Synonyms list that we hardcoded. Synonyms are chosen for the fact that they have the highest semantic score with the sentiments considered and hence they will be the best feature to compare the underlying sentiment of the tweet and to calculate the semantic score. So the tweets are scored based on their semantic score with the synonyms with the USE model from the “tensorflow_hub” library and the sentiment with the highest semantic score is considered to be the predicted sentiment label.

Advantages:
- It is an Unsupervised Learning model and hence there is no need for training data.
- As it works based on Semantic similarity between statements, it performs well in capturing the core sentiment of the statements (Positive or Negative) although they aren’t the exact labels.
Limitations:
- The programmer must be well versed and have a thorough understanding of the Sentiment Labels himself as to hardcode the Synonyms List for each Label without Redundancy.
- Performance depends on the quality of the Synonyms.
- It is not efficient for predicting Sentiment labels that are related to each other.

Accuracy : 47.5%
Doc2Vec:
Doc2vec is an NLP tool for representing documents as a vector and is a generalizing of the word2vec method. In word2vec, you train to find word vectors and then run similarity queries between words. In doc2vec, you tag your text, and you also get tag vectors. This model was chosen because it works primarily on the principle of word embeddings and these embeddings will further help us establish a relationship between related words and group similar words together. Doc2Vec’s learning strategy exploits the idea that the prediction of neighboring words for a given word strongly relies on the document also.
Know more about Doc2Vec: https://medium.com/@gaganmanku96/sentiment-analysis-using-doc2vec-model-7af08ea521fe
Approach:
Doc2Vec is a word embedding method. It creates a numeric representation of a document, regardless of its length. The pre-processed data is split into train and test split and the features are vectorized. The Doc2Vec module of “gensim.models” library is used to fit the model. The model is trained for 30 epochs with the vectorized contents of tweets as X and their respective vectorized sentiments as y.

Advantages:
- Requires a less or very basic understanding of the Sentiment labels.
Limitations:
- Requires a large amount of training data.
- The model performance entirely depends on the scale of the training dataset.

Accuracy: 45%
LSTM:
Long Short-Term Memory networks — usually just called “LSTMs” — are a special kind of RNN, capable of learning long-term dependencies. The reason that this particular model was chosen is that a basic RNN can learn dependencies however, it can only learn about recent information. But LSTM can help solve this problem as it can understand context along with recent dependency. Hence, LSTM is a special kind of RNN where understanding context can help to be useful and context is the basic key between differentiating the sentiment labels separately.
Know more about LSTM: https://towardsdatascience.com/sentiment-analysis-using-lstm-step-by-step-50d074f09948
Approach:
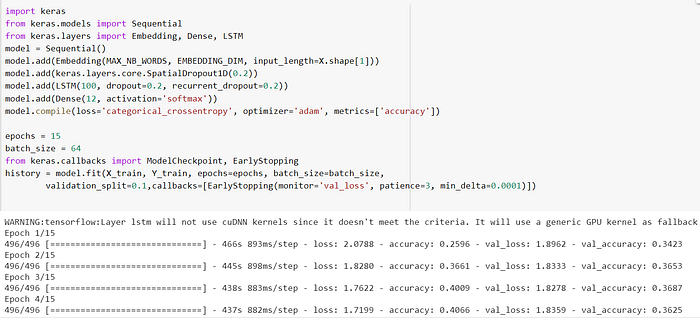
After pre-processing the data, the contents of the tweets are tokenized and pushed into a Sequential LSTM model with 4 layers. The model is trained for 15 epochs with 64 as the batch size. “categorical_crossentropy” is used as the Loss function and the “adam” optimizer is used. The model is fits with the contents of the tweets as X and its respective sentiment as y in the form of vectors.
Advantages:
- The availability of Memory cells that store previous information and the flexibility to alter the learning rates.
Limitations:
- Requires a large amount of training data.
- The model performance entirely depends on the scale of the training dataset.

Accuracy : 52.5%
Comparison:
As we can see all three models have only accuracy of about 45–50% on average. But we cannot say that these models don’t perform well based on these accuracy scores. The reason is that the sentiment labels considered are related to other sentiments and hence are redundant. For example, the sentiments of Sad and Worried are so related that, even for a human they would be difficult to differentiate at times. These kinds of outputs, where classifications happened to the closely related sentiments rather than the original sentiment label were termed as “non-Egregious” errors. Considering these non-egregious errors, the USE model was efficient in understanding the core sentiments of the statement well enough with only the Synonym list and no training data. USE model had the highest accuracy if only the egregious errors were considered misclassifications.
Conclusion:
USE model tends to have a decent performance and efficiency given that it requires no training.
We must be careful that the Sentiment labels considered are not redundant
 Written By:
Written By:
Varshnidevi B
A passionate and hardworking individual with an aim to leverage my skills in the field of data science. Self directed and a quick learner of new technologies.

Lingeshwaran R J
A passionate learner who likes to explore new domains and learn new technology stacks.

Harish SS
A highly motivated individual and passionate about exploring and implementing current technology trends.