In digital image processing and computer vision, image segmentation is the process of partitioning a digital image into multiple segments. The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze
This is a two-part article. Here in the first part, we’ll cover the basics of image segmentation, a brief overview of the process and understand why do we use image segmentation. In the second part, we’ll take a deep dive into the different types, architectures, loss functions and use-cases of image segmentation.
Introduction
Say you have decided to detour to your favorite coffee shop and come across a truck coming towards us. Our brain helps us to process the information about the vehicle approaching us and analyze the situation. Can machines do the same thing?
Some years ago, the answer would have been no, but today, the rise of computer vision and deep learning has enabled us to detect objects and infer more about them.
But what is Image segmentation, and how does image segmentation work? And what can you build with it? What are the different approaches, types, potential benefits, and limitations, and how might you use them? We are going to discuss all of that in this article.

Basics
Image segmentation is a processing technique that helps us separate an image into multiple parts called Image Objects, which can help analyze the pictures simpler. Reading this might make one confuse Image Segmentation with Object Detection or Image Recognition.

But let’s see why Image Segmentation is different from Object Detection and Image recognition. Image recognition assigns multiple labels to an entire image, and object detection, which localizes objects in an image by drawing a bounding box. Image segmentation returns granular information about the contents of an image.
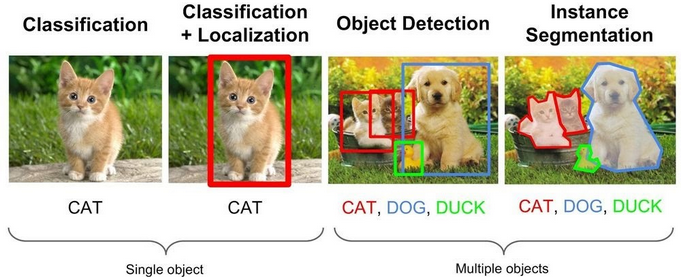
Say if you have an image of a pen. Then we can use image recognition to figure out that the image has a pen in it. But if we have a pen and an eraser, then we will have to use the concept of image Localization and Object detection to figure out the location and class of the objects.
So before detecting the objects or classifying the image, we use image segmentation to divide the image into different segments to use the essential components while processing the image.

The process of Image Segmentation
An image consists of millions of pixels; Image segmentation aims to assign each pixel to its object, which helps us split and group a specific pixel set.
This set of pixels are then labeled, and we can conclude that the pixels with the same label have something in common. Using these labels, we can specify boundaries, draw lines, and separate the essential objects in an image.
Why do we use image segmentation?
In an image recognition system, segmentation is a critical stage that helps extract the object of interest from an image further used for processing like recognition and description and to train various ML models to solve multiple problems.
Image segmentation provides us with the meaningful part of an image and dive into the granular depths of an image for further analysis. It allows us to define and analyze the boundaries of objects in a picture.
In the follow up article, we’ll discuss about the types, architectures, loss functions and use-cases of image segmentation